电影知识库问答机器人
项目代码参考: chatbot
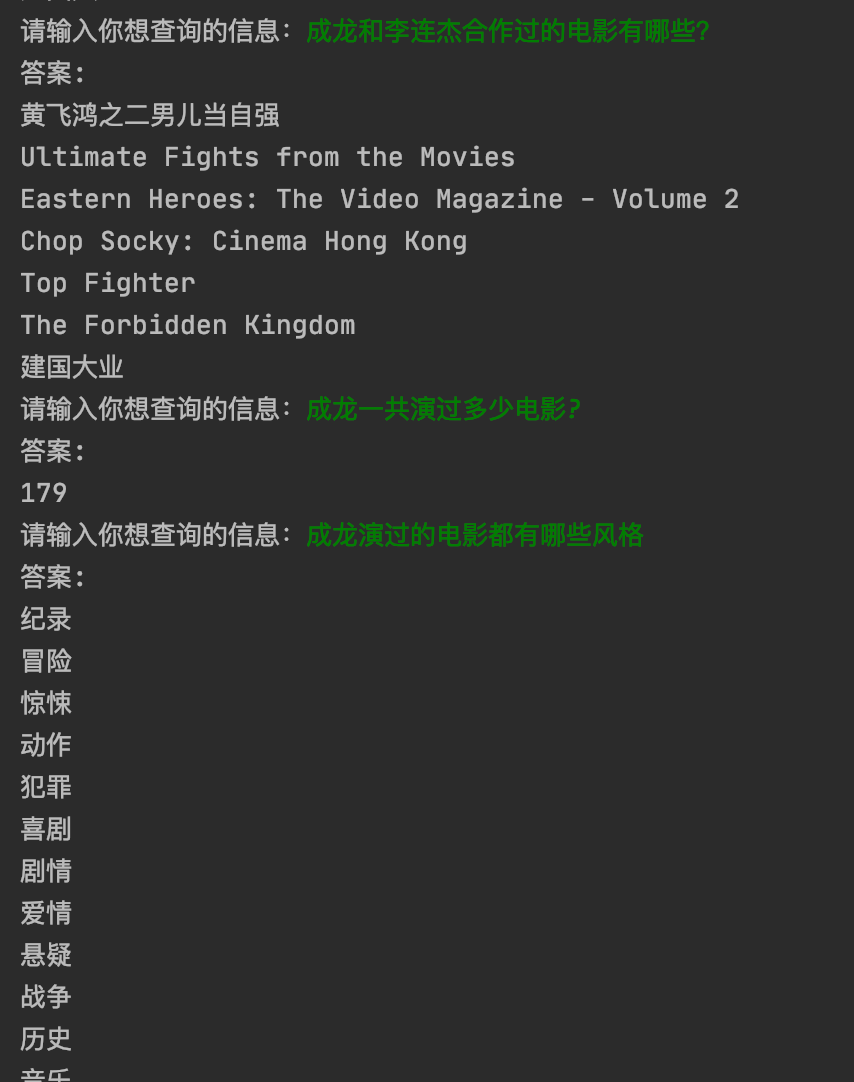
最终效果
知识图谱篇
为什么需要使用知识图谱
对原始数据流建立更加规范的数据表达,通过语义抽取、数据链接形成更多机器可理解的语义知识,从而将原本异构分散的各种数据转变为机器可计算的大数据。 将离散异构的数据通过图的方式链接成结构化的数据, 组成垂直领域的知识库, 用以对最后问题的答案查找.
准备工作
- 电影知识库的数据参考: movie data
- Neo4j图数据库
- Neo4j官网: Neo4j home
- Neo4j桌面版: Neo4j Desktop
- Neo4j服务器版: Neo4j Server
- Neo4j Docker版:
docker pull neo4j
- 简单的Neo4j语法知识: Neo4j Cypher
数据导入
-
运行你的Neo4j图数据库
启动neo4j, 打开浏览器并访问 https://127.0.0.1:7474
将以下五个数据文件移动至 neo4j 目录下的 import目录中
-
准备数据
genre.csv 用于记录所有电影的类别
gid gname 12 冒险 14 奇幻 … … person.csv 用于记录所有演员的信息
pid birth death name blography birthplace 643 1965-12-31 \N 巩俐 新加坡华裔女演员,祖籍中国山东,… Shenyang, Liaoning Province, China 695 1937-03-16 1999-04-14 乔宏 Shanghai, China …… …… …… …… …… …… movie.csv 用于记录所有电影的信息
mid title introduction rating releasedate 13 Forrest Gump 阿甘(汤姆·汉克斯 Tom Hanks 饰)于二战结束后不久出生在美国南方…… 8.3000001907 1994-07-06 24 Kill Bill: Vol. 1 新娘(乌玛·瑟曼饰)曾经是致命毒蛇暗杀小组(D.I.V.A.S)的一员…… 7.8000001907 2003-10-10 …… …… …… …… …… person_to_movie.csv 用于记录所有电影的参演人员的 关系信息 1对N
pid mid 163441 13 240171 24 …… …… movie_to_genre.csv 用于记录所有电影 是什么类型 关系信息 1对N
mid gid 79 12 82 12 …… …… -
导入数据
在命令行输入栏导入数据
导入genre.csv 用于记录所有电影的类别
//导入节点 电影类型 == 注意类型转换 LOAD CSV WITH HEADERS FROM "file:///genre.csv" AS line MERGE (p:Genre{gid:toInteger(line.gid),name:line.gname})导入person.csv 用于记录所有演员的信息
LOAD CSV WITH HEADERS FROM 'file:///person.csv' AS line MERGE (p:Person { pid:toInteger(line.pid),birth:line.birth, death:line.death,name:line.name, biography:line.biography, birthplace:line.birthplace})导入movie.csv 用于记录所有电影的信息
LOAD CSV WITH HEADERS FROM "file:///movie.csv" AS line MERGE (p:Movie{mid:toInteger(line.mid),title:line.title,introduction:line.introduction, rating:toFloat(line.rating),releasedate:line.releasedate})导入person_to_movie.csv 用于记录所有电影的参演人员的 关系信息 1对N
LOAD CSV WITH HEADERS FROM "file:///person_to_movie.csv" AS line match (from:Person{pid:toInteger(line.pid)}),(to:Movie{mid:toInteger(line.mid)}) merge (from)-[r:actedin{pid:toInteger(line.pid),mid:toInteger(line.mid)}]->(to)导入movie_to_genre.csv 用于记录所有电影 是什么类型 关系信息 1对N
LOAD CSV WITH HEADERS FROM "file:///movie_to_genre.csv" AS line match (from:Movie{mid:toInteger(line.mid)}),(to:Genre{gid:toInteger(line.gid)}) merge (from)-[r:is{mid:toInteger(line.mid),gid:toInteger(line.gid)}]->(to) -
使用数据
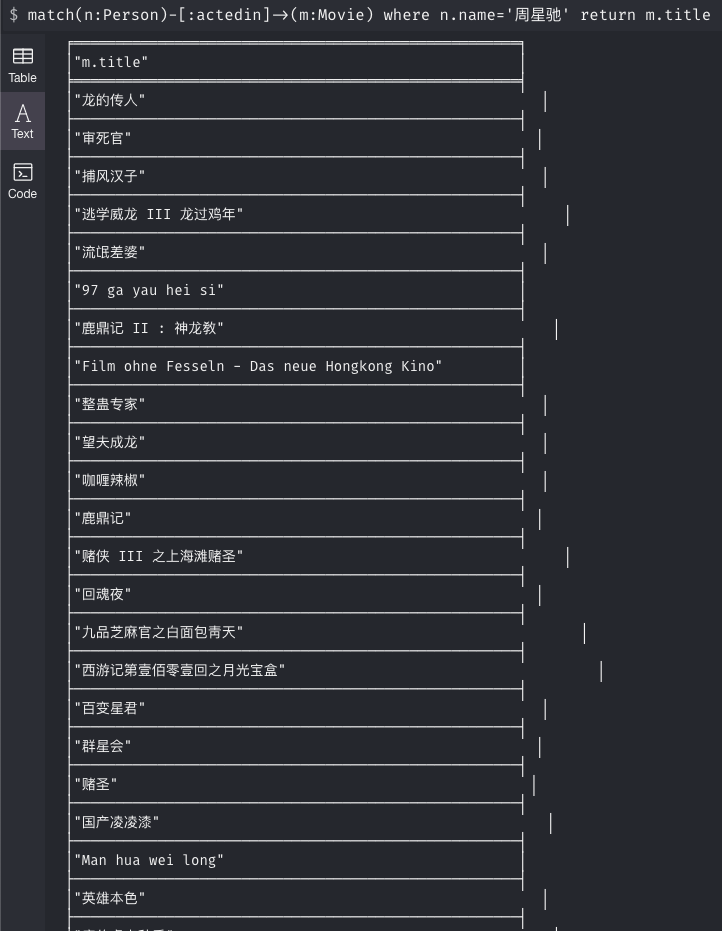
问:周星驰都演了哪些电影?
match(n:Person)-[:actedin]->(m:Movie) where n.name='周星驰' return m.title答案查找的Python代码参考: 答案搜索
查询结果展示
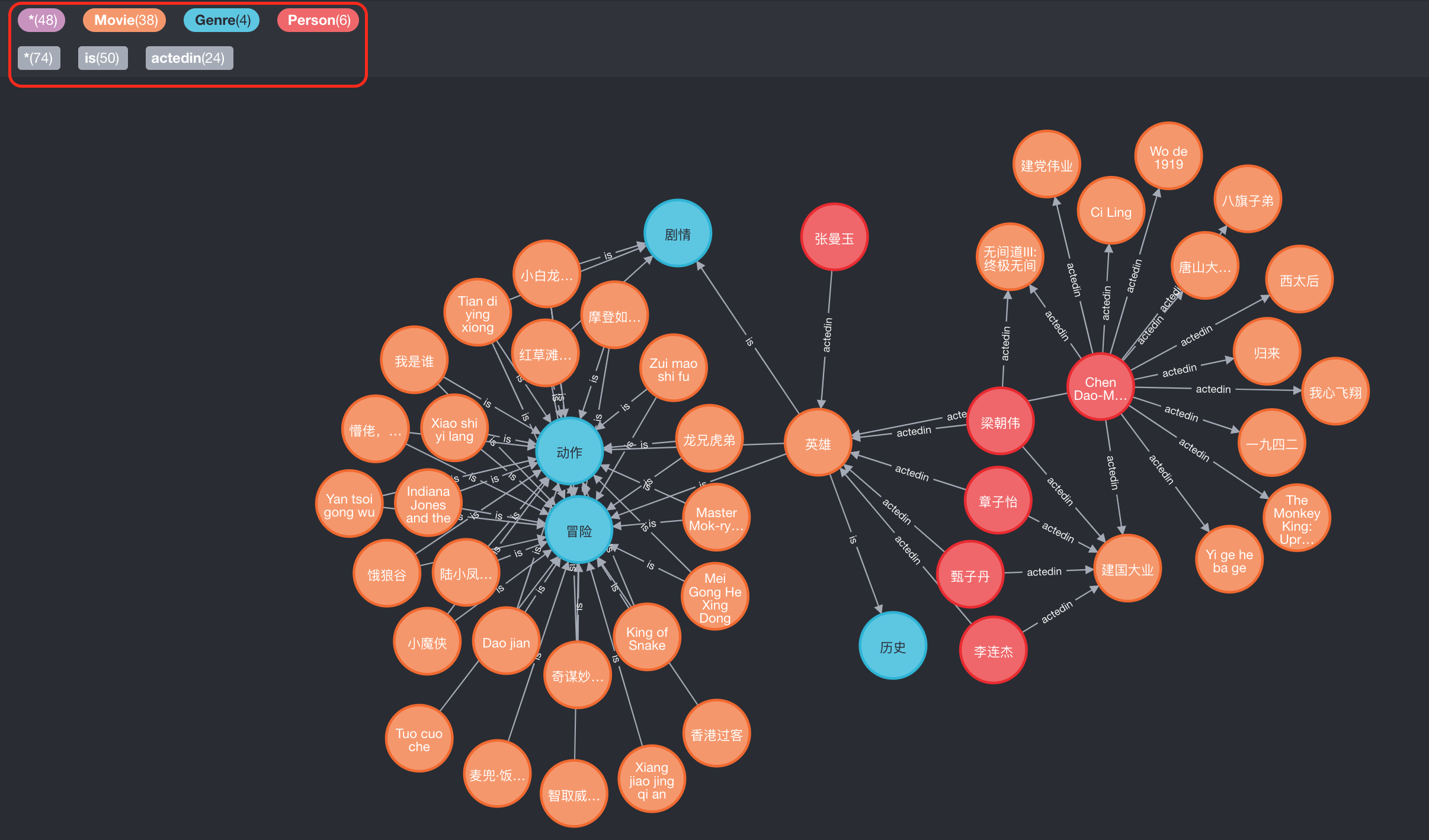
知识图谱效果
机器学习篇
为什么需要机器学习
通过机器学习对用户提出的问题, 进行问题模板分类, 关键时间 人名 地点 等词的抽取, 然后组成用户提问的真正意图, 最后在知识库中查找用户想得到的答案.
准备工作
- 高斯朴素贝叶斯原理根据自身情况学习: 参考维基百科
- Python下scikit-learn包里面的naive_bayes的使用
模型训练
-
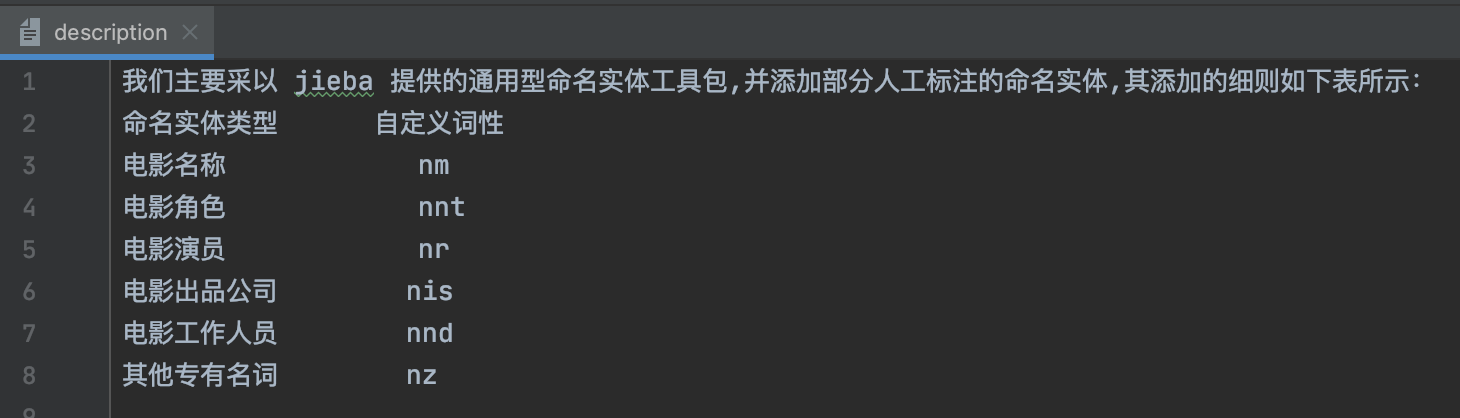
确定你问答中 用户提问的问题中的实体, 并给它自定义词性.
比如所有的演员名字是一个类型的词性, 所有电影的名称是一个类型的词性等…
后期需要添加对应的词和词性到分词器里面, 便于分词器能对不认识的词正常分词.
-
将问答机器人可以提问的问题抽象为问题模板, 并为机器学习模型 人工造训练数据.
比如某某电影的评分是多少, 有很多种问法, 这时需要将问题抽象化, 并列出来, 以此类推…
问题类别越多, 类别里的内容越多, 问答机器人能回答的问题就越准确越详细.
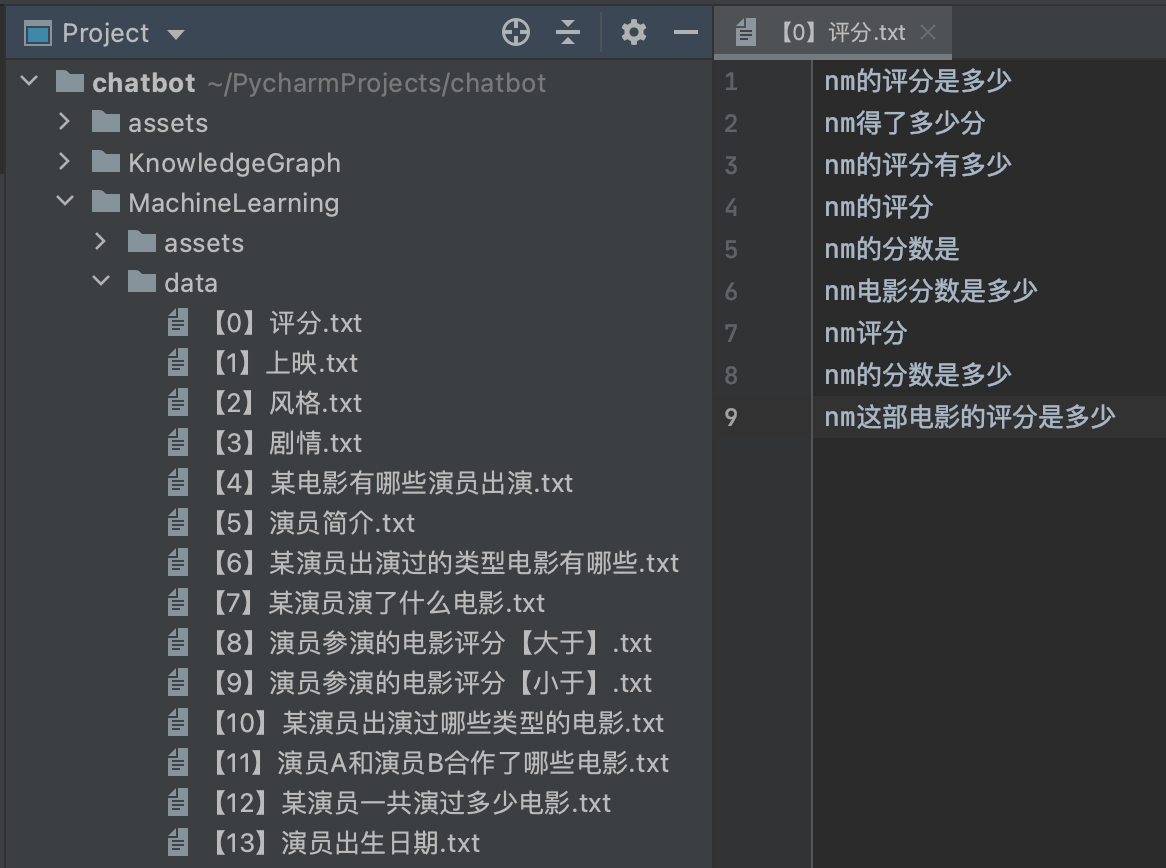
-
为当前 问题模板的所有数据分词并生成Tokenzer, 即将每一个词用数字来表示, 以便于送入机器学习模型计算.
如果增加数据, 或更换数据, 需要重新生成该文件.
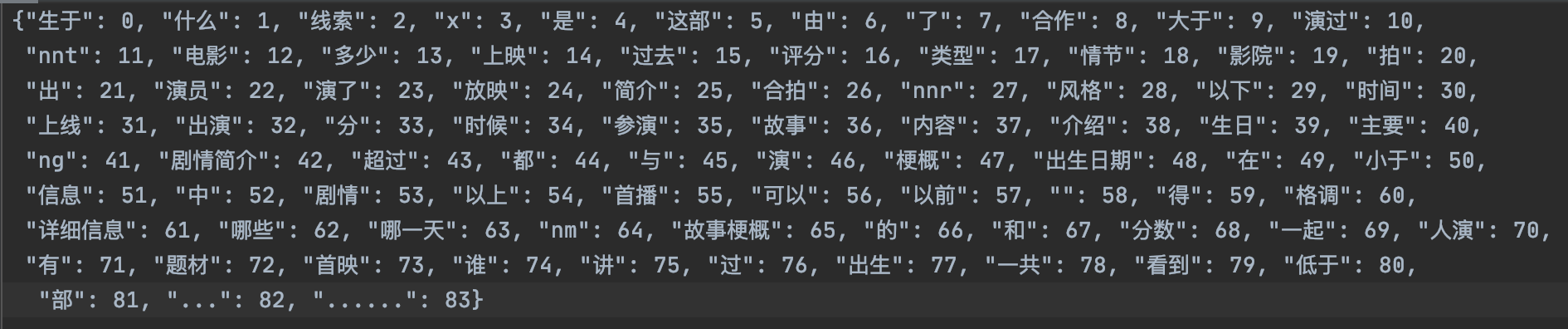
-
为所有问题模板编写问题答案查找的一个字典文件, 用于最后查找对应类别问题的答案.
注意,此处问题模板类别的顺序应和第2步中的问题顺序类别一致.
-
待
前两步准备好后, 直接执行~/MachineLearning/train.py会自动生成第 3 步的文件, 第 4 步的文件需手动修改~/MachineLearning/train.py里的字典才可生成正确的 dict, 训练问题分类模型: 训练代码参考 -
运行完
train.py因为数据量不大, 模型秒训练完毕. 直接进入下一步使用阶段. 使用问题分类模型得到用户的意图: 使用代码参考
模型使用
python run analyze_question.py
机器学习模型效果:

模型优化
- 添加问题模板的类别
- 增加每个问题模板类别的内容
- 为分词器添加 不常见词辅助分词: 词参考
- 为分词器添加 自定义词和词性
- ……